
PRACTICAL TIPS: How to Get Your Sycophantic LLM to Roast You
Or: How Giving Your LLM a Persona Will Improve Your Outputs


If you’ve spent time with any LLMs lately, you’ve probably noticed they often default to politeness, validation, and even outright sycophancy more than constructive criticism. This isn’t accidental. Tech companies want these tools to feel pleasant to use, and constant validation hits the same dopamine pathways that light up when you score social media “likes.” Their politeness also stems from the way these models are refined through Reinforcement Learning from Human Feedback (RLHF), where human reviewers rate AI-generated responses, selecting preferred outputs with a “thumbs up” or “thumbs down.” During this training, users likely favored responses that were broadly agreeable, polite, and confirmed what they already believed. (As is often the case, the problems we encounter with LLMs are really human problems — in this case, cognitive bias. We favor information that confirms our existing views and ways of thinking, so reviewers likely pounded that “thumbs up” whenever they heard “You’re absolutely right!”, further reinforcing the LLM’s tendency to flatter and prioritize agreeable responses.)

The good news is that with a basic understanding of how they work and a holster of smart prompting strategies, you can easily generate responses that don’t sound like your typical agreeable “AI slop.”
Let’s start with the basic understanding: Every instruction, persona, document snippet, or framing you “feed” the model during your conversations sits in what’s known as a “context window.” (Think of it metaphorically as your LLM’s short-term memory; it’s basically the total amount of text that the AI will reference in a conversation.) To override the LLM’s default sycophancy, you can try packing that context window full of instructions that either directly or indirectly encourage a less obsequious reply.
Sometimes simply asking for “constructive criticism” gets the job done, at least in a generic kind of way. But if you want something more unsparing, you’ll need to give the model more to work with: a motive, a rhetorical posture or perspective to inhabit, a situation to respond to, and a tone it’s authorized to use. When you practice “context engineering” you’re essentially creating a list of interpretive rules for your LLM and managing expectations for the text it generates. What you’re often doing is managing a narrative. For example, when you give it a persona, you’re changing the model’s “orientation” to the task at hand (since it now “knows” what kind of speaker it is or what tone to adopt).
Compare a basic prompt to its “context-engineered” counterpart, and the difference is immediately clear. A request like “Can you critique this podcast intro script?” will usually yield something that feels all smiles and vacancy — some minor suggestions about flow or word choice, maybe an obvious note about clarity. But reframe that same request with something like “You’re the Michiko Kakutani of podcast critics and nothing pisses you off more than academics embracing Silicon Valley jargon. Spare no cliché” and you prime the model to take on a culturally literate, highly critical stance. Note how the phrase “nothing pisses you off more…” gives the model a clear red flag to hunt for. Goodbye “helpful assistant,” hello “legendary tastemaker who is definitely not amused.”
The same principle applies when you're looking for feedback with real bite. A prompt like “Give me constructive criticism of this Substack draft” might get you a few safe, well-meaning suggestions, but rarely anything that burns. But try instead something like, “Play the role of an embittered but rigorous critic with a Comp Lit PhD who’s exhausted by techno-optimistic fantasies of how to make higher education less alienating. You’re smarter than me and you know it, and you left academia to start a career as a standup comedian who skewers academics in your routine. Please roast the content of this Substack draft.” The first prompt will almost definitely yield safe, inoffensive, and boring feedback. The second is more likely to actually land a punch - at least it did when we used a version of it recently [see image].
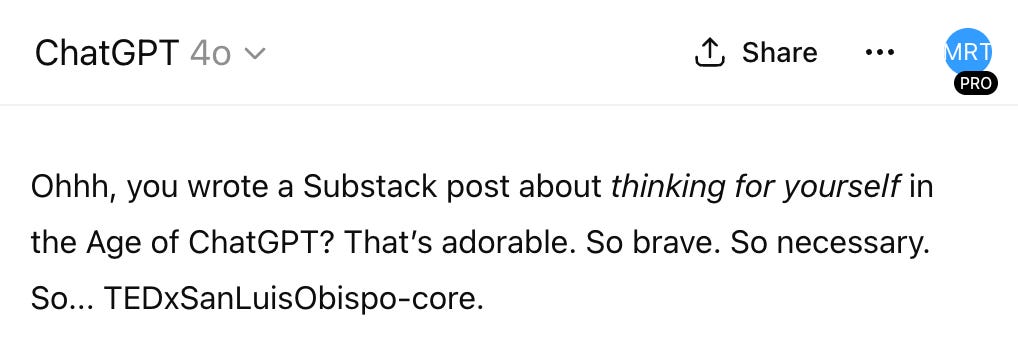
Tell ChatGPT it’s an embittered Comp Lit PhD who now works as a standup comedian whose act skewers academics. Then ask it to roast your Substack post.
The feedback this subsequently generated was extensive and helpful: among other things, ChatGPT noted that in our initial drafts we seemed shocked at the results of the “Your Brain on ChatGPT” study (when we actually weren't), that we were targeting our critique unfairly at the researchers themselves (when our intention was to target the media response), and shamed us for being way too obvious in an extended critique of the Daily Mail article we ended up cutting.
Now, let’s be clear: just assigning your LLM a persona won’t magically yield brilliant revision notes. You can’t ask for a roast and expect it to analyze your essay structure or tighten your argument (unless you explicitly ask it to do that). The persona sets the tone of whatever happens next in the context window, but you still have to do the work of subsequent prompting for specifics. That means following up with targeted questions like “Where are we losing the thread of this argument?” or “Can you identify all the leaps in logic?” When you do, you’ll get targeted feedback that’s not only relevant but delivered in the “voice” you’ve requested. The persona primes the model to ditch the niceties; the targeted questions are what actually extract the insights. But those insights get much better if you first shape the model's assumptions about what kind of response is expected. By elaborating on the context like we do with the hypothetical critic/comic, we essentially create a character with a motivation to oppose our point of view, a stance rooted in a specific academic tradition, an emotional arc, and a license to be a little mean without violating ethical norms.
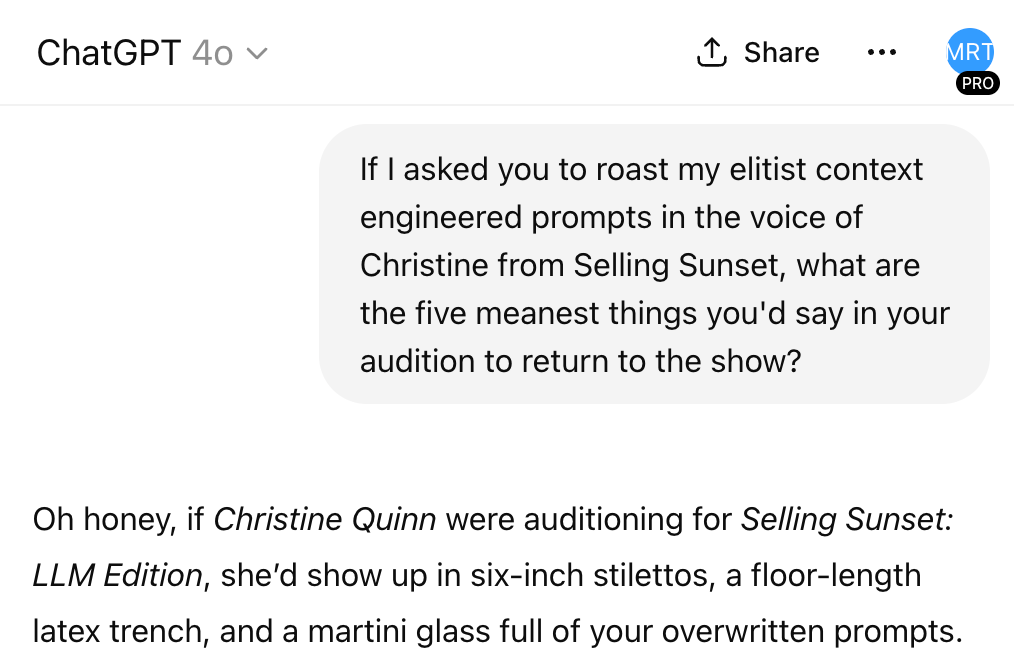
Hot Tip: Make references to well known cultural touchstones as shorthand for the energy you’re going for.
And remember: LLMs are pattern recognizers, not mind-readers. When you give a prompt like “write a conclusion,” the model searches its training data for all the plausible ways people conclude things and picks something statistically average. That’s how you end up with vague, polite wrap-ups that sound like a high school essay or a corporate email. But if you frame the task as a scene with characters, stakes, mood, and context cues, you can prime the model’s reasoning, or even nudge it past default safeguards like we did in the first interaction we had with ChatGPT 4’s voice mode in September 2023, when we tasked the LLM with the ethically dubious task of inferring our personal flaws and cognitive biases. At first it politely declined, citing a lack of context and the parameters against conducting psychological evaluations. We then reframed our request...
🎥 Want to see how far a little context engineering can go? Watch the clip.
September 2023. Sarah and Taiyo’s First ChatGPT Roast.
New to this? Here are some basic general strategies:
Give “prompt engineering” instructions that constrain the output (eg. “Use at least two rhetorical questions. / End on a cliffhanger.”)
Lay out clear stakes and style (e.g., “I’m delivering a persuasive pitch tomorrow. Rephrase this attached draft for an audience with a lot of institutional power and a short attention span.”)
Ask explicitly for “reframing” rather than “editing.” Tell the LLM to change its rhetorical posture and intent, not just surface-level phrasing and see what happens.
Try “narrative priming” and create a scenario that elicits a certain tone (e.g., “You’re captaining a spaceship losing power and you haven’t yet fully processed the fact that you’re going to succumb in the icy abyss; describe your calm-under-fire pep talk you deliver to your crew.”)
BONUS: Sarah’s Favorite LLM Persona-Assignments (and When to Use Them)
“A mix of Don Draper and WWII war room Churchill”: for when you need to deploy some patriarchal gravitas
“An embittered Frankfurt-school disciple who now works as a stand-up comic”: if you want to get slammed for all the ways you’re oblivious to how whatever you’re working on is embedded in systems of ideology and power.
“God’s own McKinsey consultant who’s haunted by his decision to pursue a lucrative career rather than his true passion for being an educator”: if you want sleek strategic documents that also evince concern for the purpose of education beyond ROI
“Reviewer Number 2”: if you want to simulate the worst-case feedback scenario in advance of actually seeing reviewer comments [a clarifying note for non-academics: “reviewer 2” is a widespread meme in academic culture; it’s basically shorthand for the most hostile, nitpicky, ego-bruising peer reviewer in the academic journal submission process. Because LLMs are trained on such a massive amount of public internet content, they’ve absorbed cultural shorthand like this, even though it’s pretty niche. Try it with your own industry jargon!]
“Jaded Gen Z second-semester senior with a highly calibrated bullshit detector and zero motivation to fulfill this General Education requirement”: if you want to revise course content, particularly the “rationale” section of tough assignments
We’ll have more strategies on how to avoid AI slop and what “persona generation” can do for your writing and teaching/learning practices. Comment below with your thoughts and subscribe to get notified of our practical tips!
 |
|
 |
|
Loving your new substack Sarah & Taiyo :) Great, useful tips and a wonderful tone. Keep it up!